In ML, data is not everything - a business perspective.
What does data mean in the ML business and how data moats are misunderstood.

Data is not everything
Early on companies and investors started shaping the narrative that the way to get an unfair advantage in ML is data. Getting access to hard to replicate datasets would mean the differentiator between successful AI startups and failures. The approach VCs took would be to fund companies that they perceived held or could hold data moats and in turn yield attractive acquisition targets for larger companies attempting to capture the data, if they were incapable of executing on the proposed market. The true competitors and acquirers in the space were seen and expected to be the FAANGs who would hoard their data and effectively acquire AI companies able to secure the data moats. I believe, this way of thinking originated through the transposition of acquisition activities by the FAANGs during the social networking era ( Youtube, Instagram etc.) Where big corps would pay large premiums to acquire data on users and fit that into their common business models: the user being the product.
The confabulation effectively is that: all data is equivalent. It turns out that this is not the case from the point of view of the FAANGs (the acquirers). Customer data ties directly into the core business units at these large organizations, yet other data for example bounded annotations for objects inside of images or video (the canonical AI picture shown in Fig-1) does not directly. Consequently, that customer data or its derivatives is more valuable and mirrors many of the large scale acquisitions. I will caveat this with the idea that large companies do buy (not acquihire) startups that hold non user data (i.e Metaweb, Like.com, Xnor.ai, AI Factory), but those acquisition tied directly to product offerings such as the Knowledge Graph, Visual Image Search at Google, and IPhone CV at Apple and face filters at Instagram.

So why are bounded image annotations not as helpful. The reason combines both performance and customer appreciation for how this data is exposed and used.
Because detection performance in computer vision models is logarithmic and we are operating in the linear range of this curve, gaining the wow factor for customers is hard.
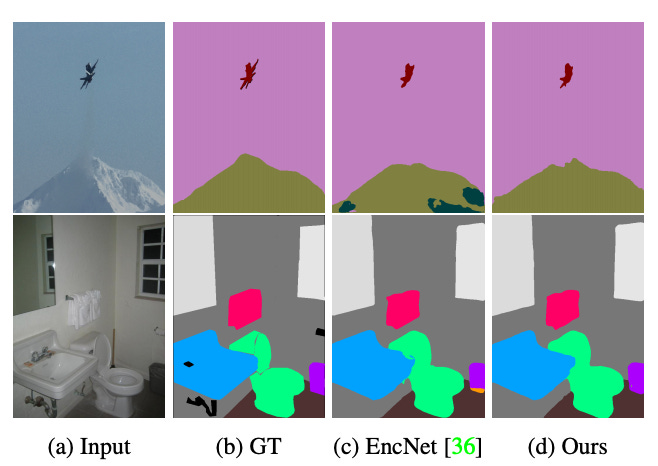
What blew my mind coming from research is that no customer really cares about a model performing .85 mIOU in precision vs one that performs at .92 mIOU (delta .07) in semantic segmentation. Performance on the logarithmic curve in ML based applications is rarely detectable by human beings when it comes into the saturation range. It requires a bunch of examples to actually see the differences, especially if the output is a general bounding box (Fig-1) or a segmentation map (Fig-2). Check out the image segmentation model below (Ours) - this is state of the art, notice the ground truth (GT) and older model EncNet [LINK], can you spot the differences? What I am pointing out here is that improvements very hard for users to appreciate.
Interestingly, this is the opposite of perception for search and retrieval systems. When people go to Google, they usually look at the top 10 pages of the results and the search engine must retrieve 10 reasonable pages out of the 1.7B webpages available. This turns out to be quite a feat and was the reason for the perceived x10 factor of Google’s search performance in the 90s.
This psychological perception is hard to replicate in ML, especially as models operate in the saturated part of logarithmic range. Imagine now that difference between the top model and number 2 is on average 7% - that means the weaker model is 7% worse at labeling pixels based on the true annotations ( please refer here for more info on IOU [LINK]).
The important thing is this pixel difference is not grouped together around one semantic section of the object, meaning it’s not like the labeled pixels are all grouped together in an object like the plane (see Fig-2), rather they are usually spread around the borders of the object.
This sort of difference in distribution actually is very well corrected for by our brains’ visual systems. In other words there’s not an ‘oh-shit’ moment when I see these annotations and I need to view them side by side to really make the assessment of their differences.
Effectively, data can give you incremental performance gains, but it may not be perceivable by the users.
This idea of data being king in AI was further compounded by the financing of countless data labeling companies most iconic of which (in SV) is Scale.ai, which spun out of YC as a python library for simplifying data annotations for ML (which I used when they first launched) and was quickly financed to providing data labeling for everything under the sun. Ironically, the data labelling business has been around for decades, notably in the outsourced data annotation world with companies like CrowdFlower. Furthermore, these new entrants are redoing the same thing with people in the loop (aka Turkers), at best perhaps aided with some semi-supervised ML systems to provide annotations.
The notion of data moats for AI has further expanded with financings of the next best thing in data: synthetic data generation companies or gaming simulator companies. This group focuses on developing synthetic data variants to circumvent the data requirements necessary for running state of the art ML models. The logic being if I can create a bunch of data synthetically, then I do not need labelers at all. Examples of companies in this space include AiReverie, DeepVisionData, Anyverse etc.
Yet, with the belief of data being the fundamental differentiator in AI, the labeling business has re-exploded. Folks in SV who weren’t part of the party have dumped a bunch of money to unseat the established players and get a piece of the pie. This was further compounded about the unrealistic promises of self driving vehicles where more data was key to achieve Level 5 autonomy. Promises that have so far outweighed realities even has order of magnitude more data has been collected. We are in 2021 and we are not that much closer to fully autonomous driving and not from lack of trying. It seems that the investment / financial ecosystem is catching up to this realization as well. Don’t get me wrong great strides have been made , but they have been incremental and much work is still left to be done.
I believe the main motivation for this sort of thinking around data originated with Silicon Valley corps and VCs who wanted it to align with the general strategy and mental model of how money was made by SaaS businesses. Further paralleling with the general cloud trends of moving everything to the cloud platforms and selling piecemeal services as engineering products (DBs, load balancers, servers etc). Effectively, large cloud providers such as AWS, GCP and Azure treat their own in house ML services as attractors for the true money makers -> their clouds.
If all data is not the same how should one think about data in ML? I believe the best way to approach this question is from the vantage point of signal processing.
If we instead think of the data distribution and how that distribution maps to the intended domain we will be able to better understand how ML models will perform. Because every ML model is simply 1 thing: a distribution (function) estimator.
Given a sample distribution a model (be it the newest neural net, SVM or just a linear estimator) attempts to create an estimate, with or without set parameters, of the sample distribution it has to train on. Then, depending on (1) how well your sample represents the full distribution of all possibilities and (2) how well your model captures those sample possibilities, will determine how well your model can predict new examples from the same global distribution.
The mental model for data being king neglects the second point: how well a model maps to the global distribution, and its corollary: how much are we willing to accept failure of that mapping.
For example, if I am in a Tesla driving down 101 and reading a book, I expect my tolerance for failure to be pretty low. If an alien jumps out on the highway I would like for my car to detect the unknown object and take safe measures to stop. Problem is it can’t, and the amount of data required to get enough instances of aliens for the model to represent that part of the distribution is exponentially greater (as you don’t see aliens appearing on highways all that often).
Most anomaly detection algorithms rely on some form of background (what is normal) and compare against that. Though aliens are different in our mind from everything we see on the road, whether Tesla’s algorithms capture the necessary features to differentiate the alien from the background in unknown. Granted this is a silly example, it holds for any class that dataset has poorly sampled and or modeled — ie where the signal to noise ratio is low. This error tolerance is what did in a lot of the reasoning around autonomous vehicle technologies chaperoned by marketing promises vs. performance. And this why companies like Tesla, Cruise and Waymo have driven millions of miles and yet can’t seem to deploy their vehicles to drive around in downtown SF or areas where there is a bit less predicability. This is a hard problem…
The idea that on average the performance of an autonomous system may be better than humans is great (famously proposed my Elon Musk), but where humans usually fail is in scenarios of being drunk or on some narcotics. It just happens many humans like drinking and using narcotics. Yet the edge cases where machines fail seem totally adaptable for human beings, adversarial research in deep learning has shown singular pixel noises causes models to fail.
Are we ok with that? is a philosophical/ethical question. Of course there are even more ethical questions of assigning blame during errors etc, I wont dive in there.
In other scenarios where ML systems are used, tolerances may be significantly lower and bad performance can actually be a feature, for example labeling training data for generating face filters on Instagram or TikTok. Or retrieving GIFs for Slack (a la Giphy) where errors are fun or actually additive to the product themselves. Pretty sure I used Giphy more, simply because it was not very good at getting very representative gifs and this made it fun and funny to use ☺️.
Properly selecting problems where ML and the domain align I think is the core takeaway here.
Do I want a pure ML system performing my surgery, probably not, but do I want it there to assist a surgeon definitely yes.
Hopefully I have cast some light on why data in ML is important and how historically poor assumptions around data have led some astray. If data is consequently viewed from the lens of signal v. noise, I think a much ‘healthier’ outcome will permeate the industry.