AI/UX - Interfacing with AI [POST 1]
Thinking about how humans interact with probabilistic technologies

ML the data production problem?
A few weeks ago, Josh Lovejoy, the head of Design at MS, published a fascinating article on designing for AI [LINK]. This was the first article that I’ve read in the last six months that sparked a whole new line of thinking about machine learning. If you have not read the article, I would recommend you do so.
The following is a mental digestion of some of the ideas and an attempt to tie them back to my own experiences.
machine learning doesn’t produce data.
To most ML practitioners, the primary concept that Lovejoy presents is not particularly novel. However, this is partially incomplete and needs further explanation to contextualize it in the machine learning space. ML, or more broadly AI, systems are simply function estimators. In layman's terms they are approximations of the world based on data that they have ‘seen’ and compartmentalized. From the perspective of lay users, ML sometimes seems like black magic. This impression is caused by estimations of very complex state spaces that we as human beings have difficulty conceptualizing leading to a wow factor by anthropomorphizing the ML system.
ML models produce data, that data can be thought of as interpolations or extrapolations (in the case of generative models) of some function. In fact, when you were in high school, you actually learned the basic interpolation/extrapolation method for linear functions, see the visualization below.

As far as math goes, these ideas are not that old. In the early 19th century, Carl Gauss attempted to approximate the movement (with a function) of celestial bodies - aka interpolate from observations and predict future locations of planets. The concept was subsequently Legendre formalized as least square regression. This technique is the first method formally covered in introductory machine learning courses [LINK].
If you consider that this line represents a model of the world (represented by the 2 red points), by drawing points along the line you are estimating or interpolating what the world looks like in parts you have not seen from those you have. There is no ‘wow factor’ when a point is pulled from a line. However more elaborate ML methods attempt to create similar models of the world. Albeit, the distinction is that these models tend to include more dimensions. Once we pass 4D, we as human beings cannot conceptualize these spaces, but mathematically they can be described and learned.
Take a 4 dimensional cube (a tesseract). This cube is an elementary example of not being able to visualize these high dimensional manifolds, for a visual see below. We can only visualize it as 3D slices through time, that's why the cube is moving - we are looking at 3D slices of a 4D object. With that in mind, many machine learning models today are looking at hundred to thousand dimensional spaces…

It turns out ML models do produce data but that data is simply some sampling from a model of the world that the ML algorithm has approximated. Effectively, this data isn’t a new description of the world, but as Josh accurately points out, an output of learned rules. The ‘wow’ factor, when a computer ‘sees’ a dog and correctly draws a bounding box around it, is simply fitting a function that exists in a high dimensional space. For a funny dystopian view of this check out what GPT-3 (a state of the art language model from OpenAI) spits out, it’s a bit concerning [LINK].
ML models do not produce ‘new’ data or out of model data. Distributional thinking is the core point I think Josh was alluding to and this is something we as humans are very poor at doing especially consciously. Perhaps this is the realm intuitions and gut feelings but less so of deep predictive thought.
Models and Empty Space
In my own experiences with AI, I find that the core problem of designing systems and algorithms that humans can take advantage of is thinking through the negative state space, what I call ‘empty space’.
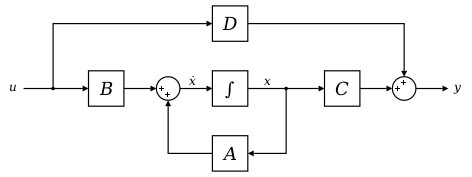
This is not a mathematically robust statement, since state space is defined by all variables representing the system. In a numerical approximation, such as a neural net, we do not have a factorized decomposition of the operators - the letters and symbols in the diagram above. We are forced to deal with numerical estimates of those objects with no clear demarcations of where they start or end. Checkout the image of what a neural network learns to respond to in 5 of its layers:
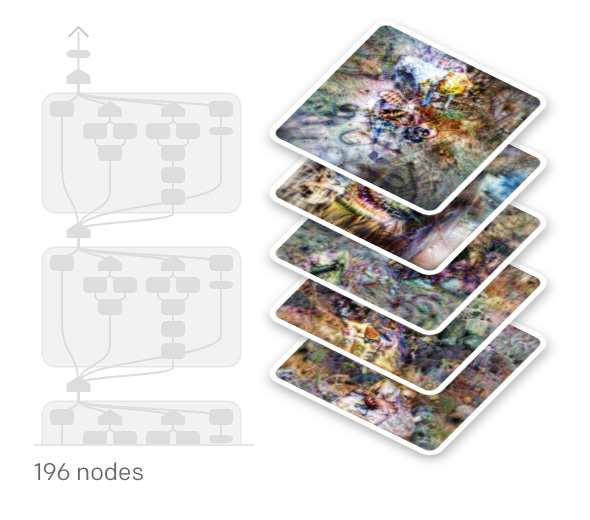
The feature visualization above gives you a feeling of what is at the heart of a trained state of the art vision model (Inception v4). To our eyes each one of those layers looks like colored Rorschach diagrams. However, these visualizations represent the combinations of inputs that the learned filters (matrices of numbers) respond maximally to. Effectively, we are seeing the parts (shapes and colors) of the training data that activate the model the most. If you trace paths from layer to layer you will find that this model has learned consistent representations of the visible world from images it was shown during its training phase.
The problem is we have no way of estimating the empty space (i.e. what the model is bad at detecting). Since we have no clear understanding of actual functional operators within the model - they are lost somewhere inside these sequential paths data goes through the model during an inference pass.
So unlike the diagram above, we cannot tell you what the model hasn’t accounted for. This is one of the reasons why many researchers call neural nets black boxes. In all fairness a lot of the field is currently working towards attempting to force factorization of these models so that they become more interpretable.
I’m going to propose that instead of trying to optimize for the reliability of AI systems, we need to be optimizing for the reliability of Human:AI collaboration.
The point Josh makes here around human:AI collaboration vs full automation has been part of the field for decades (since the 1950s). This topic is covered in great detail by historians and writers so I won’t delve on it. It dates back to the founding minds of AI - McCarthy and Engelbart. Here are some links for further reading on the topic: [LINK], [LINK], [LINK].
I do however totally agree with Josh’s (and Engelbart’s) point here. Human and AI collaboration seems like the most realistic near term goal we (as a society) will be able to achieve.
Human / AI Interfacing
From what I have seen the fundamental challenges are human more so than AI driven. Collaboration between humans and machines rests on the interaction of the two and balancing the human side of the equation seems problematic.
We as creatures of habit tend to prefer simplicity in all things tech. The simpler and less sophisticated a system for a user can be the more likely it will be massively adopted. One does not need to look for for this - open up any app on your phone.
Sadly, ML systems need to be tailored to deliver value like this. Out of the box ML lack the reliability we as humans expect.
I’m going to propose that instead of trying to optimize for the reliability of AI systems, we need to be optimizing for the reliability of Human:AI collaboration.
Capability: What is uniquely AI and what is uniquely human?
Accuracy: What does “working as-intended” mean for a probabilistic system?
Learnability: How will people build — and rebuild — trust in something that’s inherently fallible?
These 3 tenants address some of the core issues I have seen arise when people attempt to build or engage with learning systems.
What I think Josh fails to mention is that 2 of these issues (capability and learnability) and maybe to a certain extent the third are not new, but rather a different view of the same age old questions that people and technology have faced.
Dating back to the industrial revolution, defining the boundaries between what machines and humans can do and how can people trust those machines have been implicit problems technology developers have grappled with.
Capability
Partitioning capability has been a challenge before the maturation of AI. It has been compounded by ML systems significantly. This in some ways has to do with the empty space problem I mentioned earlier. It’s very hard to a priori define what a learned model is good or bad at doing. Consequently, it’s very hard to see where the machine will fail and need to rely on human inputs. The classic modern example today are autonomous vehicles. The ‘handoff problem’ has never been solved and likely will be one of the determining factors of level 5 autonomy [LINK].
Accuracy
To me the notion of accuracy is perhaps the most novel and unique property of ML/AI systems. In terms of new issues that ML developers need to design and think through for the regular users.
In the past, probabilistic systems tended to have very specialized audiences: researchers, quant traders, economists, engineers etc and would not commonly be engaged with most users. The internet revolution changed that and this trend was then compounded by AI.
Even ML researchers do not have very good ways of assessing accuracy and robustness for semantic classes or concepts outside of empirical testing. The main way this is done is through a metric which is then used on a test set of data (held out pieces of the original dataset). Then we compare the ground truth (expected) outputs to the ones our model produces. The true/false positive and true/false negative rates are then used to calculate precision (accuracy) and recall.
As an astute reader you probably caught the unspoken issue- what if the model is overfit to the dataset or the dataset is poor at capturing all the variance present in the space we are trying to model. In other words - how does a model generalize to the real world.
The notion of generalizability of models is not broached by Josh in his article, but this is one of the core problems of statistical ML research and in my opinion AI UX. Generalizability is poorly understood and one of the primary goals of statistical learning theory is to bound or describe the error in model generalization. Furthermore, it’s one of the common causes of ML and AI systems failure in the wild - i.e. the Uber/ Tesla crashes. One can drive 10s of millions of miles and still not capture all the scenarios an autonomous vehicle may encounter on the road - think of driving in New Delhi:
One may ask but what if we train the algorithms in Delhi, won’t the system learn to drive in these conditions. The answer is even if it perfectly fits the conditions of Delhi, it still does not necessarily capture oddities seen in other environments. Then what can we make the system do in cases of out of distribution anomalies? No one has a good answer - this is at the heart of the handoff problem.
Learnability
Now we come on the question of trusting fallible systems. This idea is so incredibly important IMO, in the way that it combines the other two together. Furthermore, the problem of trust in general of complex systems is a recurring issue.
Take for example the internet and stateless protocols. Because servers don’t know who requests emanate from (they are stateless), they have difficulty figuring out who is requesting a webpage for the sake of interacting with it and who is simply trying to bog down the system. There really is no way in a stateless system to solve this problem. This is also the core reason why DDoS attacks are possible - if our routers could just turn off the traffic that we didn’t want because we knew it was trying to hog resources this would be a trivial problem to solve, sadly we do not.
Stateless servers on a networks share a lot of similarities with systems that operate on probability distributions such as AI systems. Because users are dealing with empty state space and no real way of quantifying generalizability, they have no ay of knowing if a priori if a model output is reasonable. Our best bet is to try to generate a dataset that reasonably depicts the our problem domain wholly and then train a model, in turn trusting in our ability to properly select representative data. Sadly, we are not very good at this task…
There are many more thoughts I jotted down from reading this article and I will continue thinking through them in my next posts.